2024. 1. 19. 09:54ㆍ데이터 분석
제가 학부생 4학년 1학기에 보건의료빅데이터분석이라는 강의를 들었습니다. 그 때 강의를 수강하는 학우들과 같이 특정 음료를 마시고 혈당, 혈압, 체온 등을 측정한 데이터입니다. 강의 때 잠깐 며칠 투자해서 수집한거기도 하고 그렇게 큰 데이터가 아니기 때문에 간단하게 이 데이터를 가지고 분석을 진행할 건데, 이 글에서는 전처리 단계까지 진행하겠습니다.
1. 데이터 읽어오기
먼저 데이터를 읽어오도록 하겠습니다. 해당 csv파일에는 전처리를 해봐야겠지만 encoding='cp949'로 설정해야 읽어 올 수 있습니다.
df=pd.read_csv('/content/drive/MyDrive/보건의료/beverage.csv',encoding='cp949')
df.head()
2. 데이터 설명
데이터 설명입니다. 데이터에 대한 간략한 정보는 아래와 같은 코드로 조회할 수 있습니다.
df.info()총 124개의 행, 14개의 컬럼으로 구성되어 있습니다. 각 컬럼은 다음과 같습니다.
1). 컬럼
No: 넘버링
Student ID: 학생의 고유 ID
Schedule: 임상시험 측정 스케쥴
Age: (year) 나이
Gender: 남자(Male) 여자(Female)
Date: 날짜
Treatment: 섭취한 음료
RealTime: 실제 혈압 측정 시간
SBP: (mm Hg) 수축기혈압 systolic blood pressure
DBP: (mm Hg) 이완기혈압 diastolic blood pressure
PR: (bpm) 맥박수 pulse rate
RealTime.1: 실제 혈당 측정 시간
SMBG: (mg/dl) 자가혈당측정 self monitoring blood glucose
CGMS: (mg/dl) 연속혈당측정 continuous glucose monitoring system
2). 커피 음료 임상시험
HoneyPeach 허니피치
CaffeLatte 카페라떼
Mango 망고주스
VanillaLatte 바닐라라떼
3.데이터 전처리
우선 위의 데이터의 info를 보면 Age 컬럼에 Null값이 4개 존재함을 알 수 있습니다. 이 데이터는 보통 3~4학년 학우들이 많이 들었기 때문에 Null값의 학우의 정확한 나이는 모르겠지만 비슷할 것이라고 생각합니다. 그렇기 때문에 나머지 전체 학우들의 나이의 평균값을 정수형으로 집어넣겠습니다.
df=df.fillna({'Age':int(df.Age.mean())})
df.info()Null값을 전체 데이터의 평균으로 대체했습니다. 이제 Null값은 보이지 않습니다. 하지만 여기서 한가지 이상한 부분을 찾을 수 있습니다. 바로 CGMS, 연속혈당측정 컬럼인데 혈당량 (mg/dl)을 저장하고 있는 컬럼인데, 데이터의 dtype이 int 또는 float형이 아닌 object형식으로 되어있습니다. CGMS의 모든 컬럼 값들을 조회하고 문제있는 값들을 처리해보겠습니다.
df.CGMS.unique()조회 결과 '보정 전'과 '보정전'이라는 문자열이 있는것을 확인했습니다. 그럼 이 값들을 가지는 행들을 추출해서 보겠습니다.
df.loc[(df['CGMS']=='보정 전')|(df['CGMS']=='보정전'),]A12와 A28 학생은 음료를 섭취하기 이전의 스케쥴 Pre상태에서 데이터가 누락되었고, A14학생은 모든 스케쥴에서 데이터가 누락되어있습니다. 해당 데이터들도 각 Schedule에 맞는, 그리고 Treatment에 맞는 평균값을 대입하겠습니다. 우선 Schedule이 Pre는 Treatment에 영향을 받지 않기 때문에 전체 Pre 데이터를 대상으로 대입하겠습니다.
df.groupby('Schedule')['SMBG'].mean()df.loc[44,'CGMS']=int(df.groupby('Schedule')['SMBG'].mean()[3])
df.loc[52,'CGMS']=int(df.groupby('Schedule')['SMBG'].mean()[3])
df.loc[108,'CGMS']=int(df.groupby('Schedule')['SMBG'].mean()[3])이렇게 Schedule이 Pre인 데이터들의 누락 데이터들을 평균으로 채웠습니다. 다음은 음료를 섭취한 이 후 측정값들입니다. 해당 측정값들은 음료, Treatment에 영향을 받은 데이터이기 때문에 해당하는 A14학생이 섭취한 VanillaLatte의 각 Schedule에 따른 평균값을 조회해야합니다.
df.groupby(['Schedule','Treatment'])['SMBG'].mean()조회 결과 문제가 하나 더 발견된 것을 볼 수 있습니다. CafeLatte와 CaffeLatte가 있는것을 볼 수 있고, Vanilla Latte와 VanillaLatte가 있는것을 볼 수 있습니다. 이 두개를 하나로 통합시킬 필요가 있습니다.
df.loc[df['Treatment']=='CaffeLatte']df.loc[28:31,'Treatment']='CafeLatte'df.loc[df['Treatment']=='Vanilla Latte']
df.loc[80:83,'Treatment']='VanillaLatte'df.Treatment.unique()
하나의 값으로 통일하고 Treatment가 가지는 고유값들을 출력하면 4가지 음료가 정상적으로 나오는 것을 확인 할 수 있습니다. 그럼 다시 원래 하려고 했던 Schedule과 Treatment에 따른 CGMS의 평균값을 구해보겠습니다.
df.groupby(['Schedule','Treatment'])['SMBG'].mean()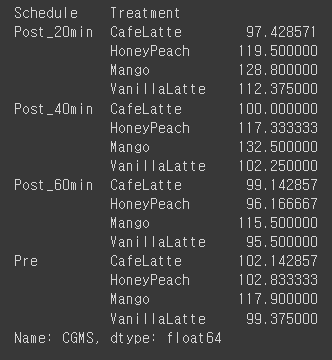
그리고 다음 값들을 해당하는 행에 대입하겠습니다.
df.loc[53,'CGMS']=df.groupby(['Schedule','Treatment'])['CGMS'].mean()[3]
df.loc[54,'CGMS']=df.groupby(['Schedule','Treatment'])['CGMS'].mean()[7]
df.loc[55,'CGMS']=df.groupby(['Schedule','Treatment'])['CGMS'].mean()[11]
df.CGMS.unique()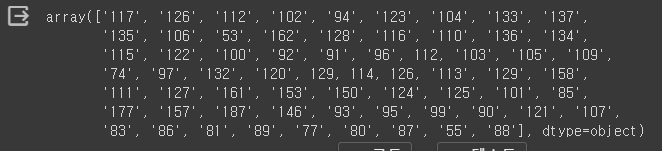
CGMS가 가지는 값들을 출력하면 정상적으로 다 나오는것을 확인 할 수 있습니다. 하지만 dtype이 여전히 object형이기 때문에 int형으로 바꿔주는 작업을 추가하겠습니다.
df=df.astype({'CGMS':'int64'})
df.info()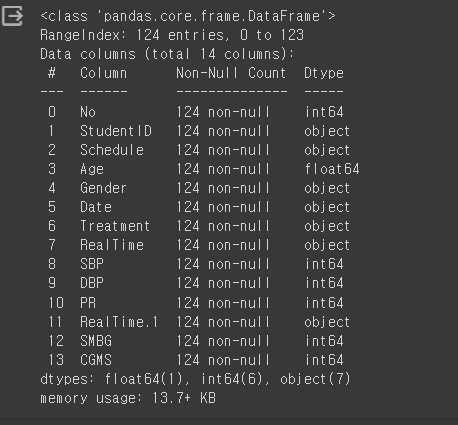
그러면 이렇게 Null값과 이상치를 제거하고 데이터를 분석하고 시각화할 준비가 끝났습니다. 다음에 시각화로 데이터에 대해서 자세하게 알아보겠습니다.
'데이터 분석' 카테고리의 다른 글
| [데이터 분석]Confusion matrix 평가 지표 해석 + 생성 (0) | 2024.02.20 |
|---|---|
| [데이터 분석] Kaggle Data Report (0) | 2024.01.16 |