2024. 1. 16. 21:55ㆍ데이터 분석
< 5조 데이터 분석 스토리텔링 : 고객 이탈 예방을 위한 이탈 고객 분석 및 대안책 수립 >
5조:김수현, 나한울, 정혜원, 한대희, 황유진
1.프로젝트 목표

최근 은행 고객 이탈률의 증가로 여러가지 문제들이 생겨났습니다.
고객의 이탈 최소화하고 고객 유지율 증가시키기 위해 여러가지 문제점들을 파악 후 해결하며 더 나아가서 신규 회원 유치까지 노려보려 합니다.
고객 이탈률 증가의 원인을 파악하기 위해서 여러가지 컬럼들을 분석하고 문제점을 파악하여 어느 부분에서 문제점이 있는지 파악하고 그 문제를 해결 및 보완하고자 합니다.
2.데이터 설명 및 확인
데이터의 수는 총 165034개의 데이터이며 , 13개의 컬럼으로 구성되어 있습니다.
컬럼의 내용은 아래와 같습니다
1 .Customer ID: 각 고객의 고유 식별자
2. Surname: 고객의 성 이름
3 .Credit Score: 고객의 신용점수
4. Geography: 고객이 거주하는 국가
5. Gender: 고객의 성별
6. Age: 고객의 나이
7. Tenure: 고객이 은행을 이용한 연수
8. Balance: 고객의 계좌 잔액
9. NumOfProducts: 고객이 이용하는 은행 상품 수(ex. 예금,적금)
10. HasCrCard: 신용카드 보유 여부
11 .IsActiveMember: 활성 회원 여부
12. EstimatedSalary: 예상 고객 급여
13. Exited: 이탈된 고객 여부
3.사용한 라이브러리
- pandas: 2.14
- numpy: 1.26.2
- matplotlib:3.8.0
- seaborn: 0.12.2
- scipy: 1.11.4
- sklearn: 1.3.2
- statsmodels: 0.14.0
4.데이터 전처리 및 시각화
- 전체 데이터의 기술 통계량
- 신용카드 보유 여부에서 1은 보유중인 고객 0은 보유하지 않은 고객
- 활성화된 고객 여부에서 1은 활성화된 고객 0은 활성화되지 않은 고객
- 이탈 여부에서 1은 이탈한 고객 0 은 이탈하지 않은 고객
- 총 데이터의 갯수는165034개이며 결측치는 없습니다.
import pandas as pd
file_path = '/content/train.csv'
data = pd.read_csv(file_path)
exited_0 = data[data['Exited'] == 0]
exited_1 = data[data['Exited'] == 1]
statistics_exited_0 = exited_0.describe()
statistics_exited_1 = exited_1.describe()
print("Exited=0 그룹:")
print(statistics_exited_0)
print("\nExited=1 그룹:")
print(statistics_exited_1)
| mean | std | min | 25% | 50% | 75% | max | |
| 신용점수 | 656.4544 | 80.10334 | 350 | 597 | 659 | 710 | 850 |
| 나이 | 38.12589 | 8.867205 | 18 | 32 | 37 | 42 | 92 |
| 거래 기간 | 5.020353 | 2.806159 | 0 | 3 | 5 | 7 | 10 |
| 계좌 잔액 | 55478.09 | 62817.66 | 0 | 0 | 0 | 119939.5 | 250898.1 |
| 이용 제품 수 | 1.554455 | 0.547154 | 1 | 1 | 2 | 2 | 4 |
| 카드 보유 여부 | 0.753954 | 0.430707 | 0 | 1 | 1 | 1 | 1 |
| 활성 회원 여부 | 0.49777 | 0.499997 | 0 | 0 | 0 | 1 | 1 |
| 예상 연봉 | 112574.8 | 50292.87 | 11.58 | 74637.57 | 117948 | 155152.5 | 199992.5 |
| 이탈 여부 | 0.211599 | 0.408443 | 0 | 0 | 0 | 0 | 1 |
신용점수: 656.45
나이: 38.13
거래 기간: 5.02
계좌 잔액: $55,478.09
이용 제품 수: 1.55
카드 보유 여부: 75.40%
활성 회원 여부: 49.78%
예상 연봉: $112,574.80
이탈 여부: 21.16%
전체 데이터의 기술통계량을 이용해 나온 평균값 입니다.
데이터 분석-시각화
이탈여부
plt.figure(figsize=(8, 5))
sns.countplot(x='Exited', data=data)
plt.title('은행 이탈 여부 분포')
plt.xlabel('Exited (0 = No, 1 = Yes)')
plt.ylabel('Count')
plt.show()
전체 고객 중에서는 은행을 이탈하지 않은 고객이 이탈한 고객보다 약 4배 정도 많았습니다. 그러나 50대 고객 층에서는 이탈한 고객이 이탈하지 않은 고객보다 약 2배 정도 많다는 결과가 나왔습니다. 이는 50대에서 이탈하는 고객의 비율이 높다는 것을 나타냅니다.

def create_age_group(age):
if age < 20:
return '10대'
elif age < 30:
return '20대'
elif age < 40:
return '30대'
elif age < 50:
return '40대'
elif age < 60:
return '50대'
elif age < 70:
return '60대'
else:
return '70대 이상'
df['AgeGroup'] = df['Age'].apply(create_age_group)
# 연령대별 이탈률
AgeGroup = ['10대', '20대', '30대', '40대', '50대', '60대', '70대 이상']
AgeExitRates = []
for i in AgeGroup:
AgeExited = df.loc[(df['AgeGroup'] == i) & (df['Exited'] == 1) , :].shape[0]
AgeData = df.loc[df['AgeGroup'] == i].shape[0]
exit_rate = round(AgeExited / AgeData, 3) if AgeData > 0 else 0
AgeExitRates.append(exit_rate)
이탈한 고객들의 나이 분포를 분석한 결과, 30대 중반에서 40대 중반까지의 고객 수가 가장 많았습니다. 그러나 연령대별 이탈률을 조사한 결과, 50대 고객 중에서 이탈하는 고객의 비율이 가장 높다는 것을 알게되었습니다. 그래서 이탈률이 높은 50대를 중심으로 추가 분석해보았습니다.
- 50대 이탈자의 기술 통계량
- 계좌 잔액이 0 인 사람은 제외함.
- 50대여서 나이의 표준편차는 2.76이며 50대중반에서 60대 초반으로 좀 더 퍼져있음
- 이탈자 값은 모두 1
- 총 데이터 4387개이며 누락된 값은 없음
| mean | std | min | 25% | 50% | 75% | max | |
| 신용점수 | 654.06 | 80.2 | 350 | 594 | 652 | 710 | 850 |
| 거래 기간 | 4.86 | 2.83 | 0 | 2 | 5 | 7 | 10 |
| 계좌 잔액 | 122428.91 | 22906.84 | 40685.92 | 108127.07 | 122314.5 | 136526.03 | 238387.56 |
| 이용 제품 수 | 1.31 | 0.68 | 1 | 1 | 1 | 1 | 4 |
| 카드 보유 여부 | 0.74 | 0.44 | 0 | 0 | 1 | 1 | 1 |
| 활성 회원 여부 | 0.31 | 0.46 | 0 | 0 | 0 | 1 | 1 |
| 예상 연봉 | 115362.19 | 50084.51 | 90.07 | 76569.55 | 121239.65 | 159793.16 | 199775.67 |
plt.figure(figsize=(8, 5))
sns.countplot(x='Exited', data=data)
plt.title('은행 이탈 여부 분포')
plt.xlabel('Exited (0 = No, 1 = Yes)')
plt.ylabel('Count')
plt.show()
plt.figure(figsize=(10, 6))
ax = sns.countplot(x='Exited', data=data, palette=['#ADCFF2', '#806BEC'])
# 레이블 설정
ax.set_xticklabels(['유지', '이탈'])
plt.title('50대 고객의 이탈 여부 분포', fontsize=15, fontweight='bold')
plt.xlabel('이탈 여부', fontsize=13)
plt.ylabel('고객 수', fontsize=13)
plt.grid(axis='y')
plt.show()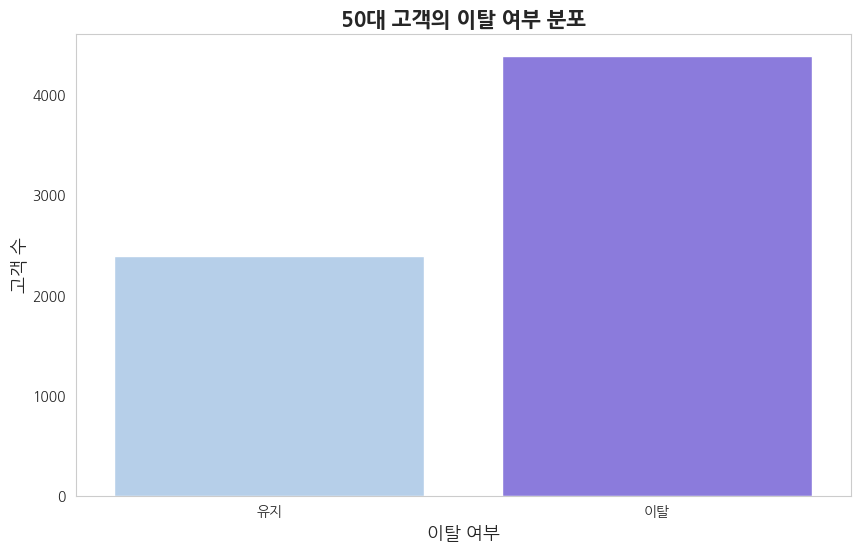
지역별 그래프
plt.figure(figsize=(12, 8))
# 카운트 플롯
ax = sns.countplot(x='Geography', data=data, palette='viridis')
# 제목 및 레이블
plt.title('지역별 고객 분포', fontsize=14, fontweight='bold')
plt.xlabel('지역', fontsize=12)
plt.ylabel('고객 수', fontsize=12)
plt.show()import matplotlib.pyplot as plt
plt.rcdefaults()
import matplotlib.font_manager as fm
# 한글
plt.rcParams['font.family'] = 'NanumGothic'
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(12, 8))
new_x_labels = ['독일', '프랑스', '스페인']
ax = sns.countplot(x='Geography', data=data, palette='cool')
# 제목 및 레이블
plt.title('50대 고객의 지역별 분포', fontsize=15, fontweight='bold')
plt.xlabel('지역', fontsize=13)
plt.xticks(range(len(new_x_labels)), new_x_labels)
plt.ylabel('고객 수', fontsize=13)
plt.show()
# 데이터 설정
labels = ['Exited', 'Stayed']
france_sizes = [48.6, 51.4]
germany_sizes = [75.9, 24.1]
spain_sizes = [51.5, 48.5]
colors = ['#ff9999','#66b3ff']
# 파이 차트 생성
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
# 프랑스 파이
axs[0].pie(france_sizes, labels=['이탈', '유지'], colors=colors, autopct='%1.1f%%', startangle=140)
axs[0].set_title('프랑스')
# 독일 파이
axs[1].pie(germany_sizes, labels=['이탈', '유지'], colors=colors, autopct='%1.1f%%', startangle=140)
axs[1].set_title('독일')
# 스페인 파이
axs[2].pie(spain_sizes, labels=['이탈', '유지'], colors=colors, autopct='%1.1f%%', startangle=140)
axs[2].set_title('스페인')
plt.tight_layout()
plt.show()

데이터를 사용하여 50대 고객의 지역별 분포에 관한 정보를 그래프로 생성한 결과, 몇 가지 중요한 인사이트를 얻을 수 있었습니다.
전체 고객 중에서는 프랑스 고객의 비중이 큰 것으로 나타났지만, 50대 고객 중에서는 독일 고객이 가장 많은 비중을 차지하고 있었습니다. 하지만 이탈 비율을 고려할 때 독일 지역에서의 이탈 비율이 75.9%로 상당히 높다는 것을 알 수 있었습니다.
active_counts = data['IsActiveMember'].value_counts()
# 파이 차트
plt.figure(figsize=(8, 8))
plt.pie(active_counts, labels=['비활성', '활성'], autopct='%1.1f%%', colors=['skyblue', 'lightcoral'], startangle=140)
plt.title('50대 고객의 활성 여부', fontsize=15, fontweight='bold')
# 그래프 표시
plt.show()
전체 고객과 50대 고객의 활성 여부를 살펴보았을 때, 50대 고객의 활성 비율이 약간 더 낮게 나타났습니다. 그리고 50대 이탈 고객들 중에서는 비활성 고객이 68.7%로 상당히 높게 나왔다는 것을 알 수 있었습니다.
5. 주요 타겟 선정 및 심층분석
5.1. 주요 타겟 선정
전체적으로 프랑스에서 가입자가 가장 많았고 50대 전후의 이탈률이 가장 많이 나타났으며 이 분석 내용에 따라서 50대의 가입자의 지역을 더 분석을 해본 결과 독일의 가입자가 가장 많은걸로 파악되었습니다.
또한 50대 가입자들의 특징을 살펴본 결과 50대 가입자들의 회원 활성화 비율이 많이 부족한것으로 보여져 이에 대응하는 대책을 세우는 방향으로 설정했습니다.
5.1.1주요 타겟에 대한 세부 방향성
1.가장 많은 이탈률을 보이는 독일지역
- 독일 지역은 가장 많은 이탈률을 보이는 지역이며 독일의 지역 특성에 맞는 혜택과 서비스 및 캠페인 등을 제공함으로써 기존 회원의 유지 및 신규 회원을 노려 볼 수 있습니다.
2.이탈률이 높은 50대 전후 고객
- 높은 이탈률을 보이고 있는 50대 전후의 고객의 상황 및 니즈를 파악하여 은퇴, 노후대비를 할 수 있는 상품을 개발하여 제공함으로써 이탈률을 낮출것이라 기대됩니다.
3.비활성화된 회원
- 비활성화된 회원이라는 케이스만을 위한 고객 서비스를 제공함으로써 비활성화된 고객이 이용할만한 메리트를 만들어 활성화 시켜 고객 유지율을 높일 수 있고 고객과의 상호작용을 통해 기존의 혜택 또는 서비스를 보완 할 수 있습니다.
4.장기 이용고객과 우수 고객
- 장기 이용고객과 우수 고객에게는 고객을 위한 특별 우대 서비스 및 멤버쉽등을 이용하여 고객 유지율을 높일 수 있습니다.
5.2 심층분석
5.2.1. 50대 고객 심층 분석- 그래프 이용
가설1: 50대 고객(Age) 중 거래기간(Tenure)이 길수록, 이탈률이 낮다.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터 불러오기 (예시 데이터)
train_data = pd.read_csv('/kaggle/input/playground-series-s4e1/train.csv') # 데이터 파일 경로를 적절히 수정
# 가설에 따른 분석
plt.figure(figsize=(12, 6))
# 50대 고객에 대한 데이터 필터링
age_50s_data = train_data[(train_data['Age'] >= 50) & (train_data['Age'] < 60)]
# 거래 기간(Tenure)에 따른 이탈율 시각화 (Violin Plot)
sns.violinplot(x=age_50s_data['Exited'], y=age_50s_data['Tenure'])
# 전체 표에 점선 추가
plt.axhline(y=age_50s_data['Tenure'].mean(), color='gray', linestyle='--', label='Mean Tenure')
plt.legend() # 범례 표시
plt.title('Tenure vs. Exited for Customers in their 50s', fontsize=15)
plt.xlabel('Exited', fontsize=12)
plt.ylabel('Tenure', fontsize=12)
plt.xticks(ticks=[0, 1], labels=['Not Exited', 'Exited']) # x축 눈금 설정
# x축에 이탈율 표시
ax2 = plt.twiny()
ax2.set_xlim(0, 1)
ax2.set_xticks([0.25, 0.75])
ax2.set_xticklabels(['Low Churn Rate', 'High Churn Rate'])
ax2.set_xlabel('Churn Rate')
plt.yticks(ticks=range(int(age_50s_data['Tenure'].min()), int(age_50s_data['Tenure'].max()) + 1)) # y축 눈금 설정
plt.show()
ㄱ. Violin Plot을 활용한 Tenure과 Exited 관계 시각화
- 50대 고객 중 거래 기간(Tenure)에 따른 이탈 여부를 Violin Plot으로 시각화함
- 이탈하지 않은 그룹과 이탈한 그룹 간의 거래 기간 분포를 비교하여 특징을 도출함
ㄴ.결과 관찰
- 6년 이상의 거래 기간을 기준으로 살펴보았을 때, 우측(Exited)의 수치가 좌측(Not Exited)의 수치보다 상대적으로 적은 것을 확인할 수 있음
- 이탈한 고객(Exited = 1)은 특정 거래 기간 범위에서 보다 집중된 분포를 나타내어 패턴을 시사할 수 있음
- 이탈하지 않은 고객(Exited = 0)의 경우, 거래 기간의 분포가 더 넓게 펼쳐져 있어 다양한 기간을 보여줌
ㄷ.결과 해석
- 50대 고객 중 거래 기간이 긴 경우 이탈 빈도가 낮아짐
- 50대 고객 중 거래 기간이 짧은 경우 이탈 가능성이 더 높음
가설2: 50대 고객 중 신용점수(CreditScore)가 낮을수록, 이탈률이 높다
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터 불러오기 (예시 데이터)
train_data = pd.read_csv('/kaggle/input/playground-series-s4e1/train.csv') # 데이터 파일 경로를 적절히 수정
# 50대 고객에 대한 데이터 필터링
age_50s_data = train_data[(train_data['Age'] >= 50) & (train_data['Age'] < 60)]
# 이탈자와 비이탈자를 구분하여 데이터 분리
exited_data = age_50s_data[age_50s_data['Exited'] == 1]
not_exited_data = age_50s_data[age_50s_data['Exited'] == 0]
# CreditScore 분포 시각화
plt.figure(figsize=(12, 6))
sns.histplot(exited_data['CreditScore'], label='Exited', color='red', alpha=0.5, kde=True)
sns.histplot(not_exited_data['CreditScore'], label='Not Exited', color='blue', alpha=0.5, kde=True)
plt.title('CreditScore Distribution for 50s Customers (Exited vs. Not Exited)', fontsize=15)
plt.xlabel('CreditScore', fontsize=12)
plt.ylabel('Density', fontsize=12)
plt.legend()
plt.show()
ㄱ. 히스토그램과 KDE를 이용한 CredaitScore와 Exited 관계 시각화
- 50대 고객 중 신용 점수(CreditScore)에 따른 이탈 여부를 히스토그램과 KDE로 시각화함.
- 이탈하지 않은 그룹과 이탈한 그룹 간의 신용 점수 분포를 비교하여 특징을 도출
ㄴ. 결과 관찰
- 특히 신용점수가 600점 후반대의 50대 이용자의 이탈률이 가장 높음
- 이탈은 전반적으로 500점 후반대부터 700점 초반대의 50대 이용자 중에서 주로 발생함
- 이탈률과 비이탈률이 가장 큰 폭으로 차이가 나는 구간은 600점 중반의 이용자임
- 700점대 이후로는 이탈률이 눈에 띄게 감소하는 것을 확인할 수 있음
ㄷ. 결과 해석 (인사이트)
- 신용점수와 이탈률이 뚜렷한 상관관계가 띈다고 보기는 어려움
- 50대 고객 중 신용점수가 낮을수록 이탈률이 높다고 판단하기는 어려움
- 그러나 600점대의 50대 이용자 중 비이탈률 대비 이탈률 폭이 큰 차이를 띄는 것을 확인할 수 있음
- 즉, 600점대 50대 이용자의 이탈 예방을 위한 대책 마련이 필요한 상태로 보여짐
가설3: 50대 고객 중 계좌잔액(Balance)가 낮을수록, 이탈률이 높다.
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 데이터 불러오기 (예시 데이터)
# 파일 경로를 적절히 수정
train_data = pd.read_csv('/kaggle/input/playground-series-s4e1/train.csv')
# 50대 고객에 대한 데이터 필터링
age_50s_data = train_data[(train_data['Age'] >= 50) & (train_data['Age'] < 60)]
# 계좌잔액(Balance)에 따른 이탈율 시각화 (Violin Plot)
plt.figure(figsize=(12, 6))
sns.violinplot(x='Exited', y='Balance', data=age_50s_data, palette="muted", split=True)
plt.axhline(y=age_50s_data['Balance'].median(), color='black', linestyle='--', label='Median Balance')
plt.title('Balance vs. Exited for Customers in their 50s', fontsize=15)
plt.xlabel('Exited', fontsize=12)
plt.ylabel('Balance', fontsize=12)
plt.xticks([0, 1], ['Not Exited', 'Exited'])
plt.legend()
plt.show()
ㄱ. 히스토그램과 KDE를 활용한 Creditscore와 Exited 관계 시각화
- 50대 고객 중 계좌잔액(Balance)에 따른 이탈 여부를 Violin Plot로 시각화함
- 점선은 전체 데이터의 계좌 잔액 중간값을 나타냄
ㄴ. 결과 관찰
- Not Exited 그룹과 Exited 그룹 간의 계좌 잔액 분포 차이가 관찰됨
- 100,000 ~ 150,000 달러의 계좌 잔액을 가진 50대 고객의 이탈률이 비교적 높음
- 낮은 계좌 잔액의 범위에서 보았을 때, 상대적으로 비이탈률이 더 높은 경향을 띄고 있음
- 그러나 전체적으로 낮은 계좌 잔액의 50대 고객이 중앙값 이상의 잔액을 보유한 고객보다 더 높은 이탈률을 보이고 있음
ㄷ. 결과 해석 (인사이트)
- 계좌 잔액이 낮은 고객들이 이탈하는 경향이 나타남
- 계좌 잔액이 낮은 고객에 대한 서비스 개선이나 타겟 마케팅이 필요함을 시사함
50대 고객 심층 분석- 그래프 이용 결과 종합
- Tenure는 Exited에 영향을 주는 것으로 보임
- CreditScore는 비슷한 분포를 띄고 있으나, 600점대 후반에서 700점대 후반까지 이탈률이 높게 측정됨.
- Balance는 낮은 고객들이 이탈하는 경향이 보임
5.2.2. 전체 고객 심층 분석- 2 sample t-test 이용
독립변수:CreditScore, Age, Tenure, Balance
종속변수:Exited
- 2 sample t-test 검정 방식을 이용하여, 종속변수에 대해 각 독립변수가 통계적으로 유의한 결과를 보이는지에 대해 검정
- 표본의 크기가 크기 때문에 중심극한정리에 의해 정규성을 가진다고 가정
- Balance의 값이 0인 데이터는 제거 후 진행
- Exited가 0인 그룹과 1인 그룹의 샘플 차이가 많아 통일한 크기만큼 샘플링하여 진행
- 각 그룹은 모집단은 아니나, 샘플의 수가 충분히 크기 때문에 샘플들은 모집단과 같은 분포를 가지게됨.
- ɑ=0.05
- 가설설정
- H0:Exited 그룹간의 독립변수(CreditScore, Age, Tenure, Balance)에 대한 평균은 같다.
- H1:Exited그룹간의 독립변수(CreditScore, Age, Tenure, Balance)에 대한 평균은 다르다.
nonzero=train_data[train_data['Balance']!=0].reset_index(drop=True)
df_0=nonzero.loc[nonzero['Exited']==0,['CreditScore','Age','Tenure','Balance']].reset_index()
df_1=nonzero.loc[nonzero['Exited']==1,['CreditScore','Age','Tenure','Balance']].reset_index()ㄱ.결과
-CreditScore
t, p=stats.ttest_ind(df_0.CreditScore,df_1.CreditScore)
t, p
if p < 0.05:
print("H0 기각: 두 샘플 간에는 통계적으로 유의한 차이가 있습니다.")
else:
print("H0 채택: 두 샘플 간에는 통계적으로 유의한 차이가 없습니다.")
print(round(p,5))p≈0
H0기각
Exited 그룹간의 CreditScore는 통계적으로 유의미한 차이가 존재함.
-Age
p≈0
H0기각
Exited 그룹간의 Age는 통계적으로 유의미한 차이가 존재함.
-Tenure
p≈0
H0기각
Exited 그룹간의 Tenure는 통계적으로 유의미한 차이가 존재함.
-Balance
p≈0.675
H0채택
Exited 그룹간의 Balance는 통계적으로 유의미한 차이가 존재하지않음.
5.2.3. 50대 고객 심층 분석- 2 sample t-test 이용
- 위와 거의 동일한 방법과 배경으로 검정 실시.
- 추가적으로 가장 높은 이탈률을 보이는 50대를 타겟으로 선정
- 50대 고객에 Age가 정해져있기 때문에 종속변수에 Age는 제거
- ɑ=0.05
- 가설설정
- H0:Exited 그룹간의 독립변수(CreditScore, Tenure, Balance)에 대한 평균은 같다.
- H1:Exited그룹간의 독립변수(CreditScore, Tenure, Balance)에 대한 평균은 다르다.
def categorize_age(age):
if age<20:
return '10s'
elif age<30:
return '20s'
elif age<40:
return '30s'
elif age<50:
return '40s'
elif age<60:
return '50s'
elif age<70:
return '60s'
else:
return '70+'
train_data['Age_range']=train_data['Age'].apply(categorize_age)
nonzero=train_data[train_data['Balance']!=0].reset_index(drop=True)
df_0_50s=nonzero.loc[(nonzero['Exited']==0)&(nonzero['Age_range']=='50s'),['CreditScore','Tenure','Balance']].reset_index(drop=True)
df_1_50s=nonzero.loc[(nonzero['Exited']==1)&(nonzero['Age_range']=='50s'),['CreditScore','Tenure','Balance']].reset_index(drop=True)
ㄱ.결과
-CreditScore
t, p=stats.ttest_ind(df_0_50s.CreditScore,df_1_50s.CreditScore)
t, p
if p < 0.05:
print("H0 기각: 두 샘플 간에는 통계적으로 유의한 차이가 있습니다.")
else:
print("H0 채택: 두 샘플 간에는 통계적으로 유의한 차이가 없습니다.")
print(round(p,5))p≈0.406
H0채택
Exited 그룹간의 CreditScore는 통계적으로 유의미한 차이가 존재하지않음.
-Tenure
p≈0.066
H0채택
Exited 그룹간의 Tenure는 통계적으로 유의미한 차이가 존재하지않음.
-Balance
p≈0.305
H0채택
Exited 그룹간의 Balance는 통계적으로 유의미한 차이가 존재하지않음.
ㄴ.결과 종합
- 전체적으로 보았을 때 Balance를 제외한 CreditScore, Age, Tenure에 대해서 통계적으로 유의미한 차이가 존재.
- 그러나 가장 높은 이탈률을 보이는 50대를 대상으로 심층 분석한 결과 50대에 한해서는 CreditScore, Tenure, Balance는 유의미한 차이가 존재하지 않으므로 50대의 이탈 여부를 결정하는 것은 다른 변수또는 외부환경에 있을 확률이 크다.
5.2.4. 교차분석
독립변수:Exited제외 범주형 변수(HasCrCard, IsActiveMember, Gender, BalLevel)
종속변수:Exited
- 범주형 변수간에 Exited외 상관관계를 찾고자 교차분석을 수행
- 가설설정
- H0:Exited 와 독립변수(HasCrCard,IsActiveMember,Gender,BelLevel)는 서로 독립이다.
- H1:Exited 와 독립변수(HasCrCard,IsActiveMember,Gender,BelLevel)는 서로 독립이 아니다.(상관관계가 있다.)
- 전처리 과정
# 데이터 불러오기
import pandas as pd
train = pd.read_csv('C:/Users/skrtk/Desktop/데엔 교육/data/train.csv')
data = train.drop(['id', 'CustomerId', 'Surname', 'Geography'], axis=1)
# 무잔고 제외한 데이터
data_ybal = data.loc[data['Balance'] != 0, :]
data.shape[0]
data_ybal.shape[0]
# 파생변수 생성해보기
# 잔고에 따른 파생변수1
import numpy as np
count1, bin_dividers1 = np.histogram(data_ybal['Balance'], bins=3)
a1 = np.linspace(data_ybal['Balance'].min(), data_ybal['Balance'].max(), 4)
data_ybal['BalLevel'] = pd.cut(data_ybal['Balance'], bins = bin_dividers1, include_lowest=True,
labels=['저소득','중간소득', '고소득'])
# 나이대에 따른 파생변수2
data_ybal['AgeGroup'] = pd.cut(data_ybal['Age'], bins = [10, 20, 30, 40, 50, 60, 70, 100],
labels=['10대', '20대', '30대', '40대', '50대', '60대', '70대 이상'],
include_lowest=True, right = False)
data_ybal.info()
# 나이대 정하기 위한 이탈율 확인
# 각 나이대 이탈자/ 각 나이대 전체 사용자
dyd = data_ybal
AgeGroup = ['10대', '20대', '30대', '40대', '50대', '60대', '70대 이상']
for i in AgeGroup:
AgeExited = dyd.loc[(dyd['AgeGroup'] == i) & (dyd['Exited'] == 1) , :].shape[0]
AgeData = dyd.loc[dyd['AgeGroup'] == i].shape[0]
print(i, round(AgeExited / AgeData, 3))
# 50대로 결정
data_ybal_50 = dyd.loc[dyd['AgeGroup'] == '50대', :]
# 50대 대상 분석이므로 나이대 변수 drop
data_ybal_50.drop('AgeGroup', axis=1, inplace=True)
dy5 = data_ybal_50
dy5.info()
# 상관계수와 유의확률 출력
import pingouin as pg
table = pg.rcorr(dy5, stars=False)
# 더미변수화(원핫인코딩), 더미변수
#상관관계 시각화
corr = dy5.corr()
import seaborn as sns
sns.heatmap(corr, vmin=-1, vmax=1, cmap='vlag', annot=True) # ㅗㅜㅑ
dy5_dm = pd.get_dummies(dy5, columns = ['Gender','BalLevel'], drop_first=True)
# 신용카드 사용 여부와 활성회원 여부는 이미 이분형 범주형 변수이므로 원핫인코딩 X
# 스케일링
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
scaler.fit(dy5_dm)
dy5_dm_sc = scaler.transform(dy5_dm)
dy5_dm_sc = pd.DataFrame(dy5_dm_sc)
dy5_dm_sc
# data_sc에 컬럼 붙이기
dy5_dm_sc.columns = dy5_dm.columns
# 다중공선성 확인
from statsmodels.stats.outliers_influence import variance_inflation_factor
vif = pd.DataFrame()
vif['VIF Factor'] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif['variable'] = X.columns
print(vif)
col = ['HasCrCard', 'IsActiveMember', 'Gender_Male','BalLevel_중간소득', 'BalLevel_고소득']
for i in col:
cross_data = pd.crosstab(index = dy5_dm_sc['Exited'], columns = dy5_dm_sc[i],
margins=False)
from scipy.stats import chi2_contingency
chi2, p, dof, expected = chi2_contingency(cross_data)
msg = 'Test Statistic: {}\np-value: {}\nDegree of Freedom: {}'
print(f'<Exited and {i}>')
print(msg.format(chi2, p, dof))
if p < 0.05:
print('dependent')
else:
print('independent')
print(expected)
print('---------------------------')
<ㄱ. 결과
-HasCrCard
p≈0.061
H0 채택
Exited와 HasCrCard는 서로 독립이다.
-IsActiveMember
p≈0.00
H0 기각
Exited와 IsActiveMember는 서로 독립이 아니다.
-Gender
p≈0.00
H0 기각
Exited와 Genderr는 서로 독립이 아니다.
-BalLevel_mid
p≈0.00
H0 기각
Exited와 BalLevel_mid는 서로 독립이 아니다.
-BalLevel-high
p≈0.00
H0 기각
Exited와 BalLevel_mid는 서로 독립이 아니다.
ㄴ. 결과 종합
- Exited와 범주형 변수들의 독립성을 검정하였을 때 상관관계가 나타나지 않는 결과는 HasCrCard밖에 없었다.
- 다른 변수들은 Exited와 독립관계가 아니다.
5.2.5. 50대 고객 회귀분석(OLS)
독립변수:Age, Tenure, CreditScore
종속변수:NumOfProducts
# NumOfProducts에 대해 회귀분석
# 종속변수 재정의
X1 = dy5_dm_sc[['Age', 'BalLevel_중간소득','BalLevel_고소득',
'Tenure', 'CreditScore']]
y = dy5_dm_sc['NumOfProducts']# 회귀분석
import statsmodels.api as sm
X1_ad = sm.add_constant(X1)
model = sm.OLS(y, X1_ad).fit()
print(model.summary())
ㄱ.결과 .
- 각 P값이 유의미한 값은 const, BalLevel_mid 를 제외하고는 유의미하지 않음.
- R-squared의 값이 0.001로 종속 변수의 변동 중 모델이 설명하는 비율이 매우 낮기때문에 위의 결과도 신뢰도가 매우 떨어짐.
6.최종 문제점 및 해결책 제시
은행은 현재 많은 고객 이탈로 인한 신뢰도 하락과 수익 감소의 문제를 겪고 있습니다. 또한, 활성화된 고객의 부족으로 신규 상품 및 이벤트 성공 가능성의 감소는 은행의 장기적인 성장 전략에 큰 영향을 미칠 수 있습니다.
특히 다른 고객들에 비해서 높은 잔액과 평균연봉을 가지고 있는 50대 전후의 고객들의 이탈은 은행의 자금 감소로 및 경쟁력 저하로 이어질 수 있습니다.
해결 방안으로는 다음과 같습니다:
- 국가별 특색을 고려한 마케팅
- 예를 들어 독일 고객을 위한 맥주 캐시백 혜택 제공할 수 있습니다.
- 예상 효과: 고객 참여 유발, 브랜드 충성도 증가, 경쟁사 대비 좋은 인식 확보 - 지역 특색 활용
- 지역사회와 협력을 통한 축제를 개최할 수 있습니다.
- 예상 효과: 고객 참여 유발, 브랜드 이미지 강화, 고객 충성도 및 장기적 관계 구축 - 낮은 잔액의 고객들을 위한 저렴하고 간편한 은행 서비스 제공
- 잔액이 낮은 고객들의 이탈 비율이 높기 때문에 금전적인 부담을 최소화 시킵니다.
- 예상 효과: 금전적 부담 감소, 은행 서비스 접근성 증가, 신규 고객 유치 - 예금 이자를 높인 상품 출시
- 잔액에 상관없이 혜택을 받을 수 있는 예금 이자를 높인 상품을 출시하여 고객들의 이탈률을 낮추며 유지율을 높이고 신규 회원 유치까지 노려볼 수 있습니다.
- 예상 효과: 이탈률 감소, 유지율 향상, 경쟁 은행과의 우위 확보 - 은퇴 및 연금 관리 컨설팅 제공
- 50대 전후의 고객들을 위한 맞춤 서비스로 높은 이탈률을 가진 50대 고객들의 이탈률을 낮출 것이라 기대되며, 신규 회원 유입으로도 이어질 수 있습니다.
- 예상 효과: 고객의 금전적 불안감 감소, 신뢰 구축, 고객 충성도 및 은행 신뢰성 향상
7.프로젝트 평가
아쉬운점
- 초반 데이터 분석의 방향성 및 계획을 수립하지 않아서 작업시간이 많이 소요되어 다양한 변수들을 분석하고 검증하는데 시간적인 부족함이 느껴져서 아쉬움.
- 이탈률이 높은 50대 고객들을 분석 대상으로 선정하였는데, 매우 밀접한 변수를 찾아내지 못한 부분과 너무 이탈률에만 초점을 맞춘것에 아쉬움이 존재
느낀점
- 팀원들과 협동과 의사소통을 통해 프로젝트를 해결하려는 과정이 좋았으며, 배운 것들을 복습하고 이해하는 좋은 성장과정이었음.
- 작은 프로젝트지만 이런 경험을 하는것이 좋았으며 이 후 프로젝트에도 도움이 될 것으로 예상
'데이터 분석' 카테고리의 다른 글
| [데이터 분석]Confusion matrix 평가 지표 해석 + 생성 (0) | 2024.02.20 |
|---|---|
| [데이터 분석]보건의료빅데이터분석 데이터 전처리 (0) | 2024.01.19 |